通过大模型微调技术来打造自己的专业助手
通用大模型被训练为可用于处理多种任务,包括普通对话,文本写作,计算和程序编码等,但对于某些特定任务他们并不那么擅长,大模型微调技术则可以解决这个问题。

大模型微调技术之前就了解过,大概是8月份左右吧,当时看到OpenAI推出了微调服务,于是就试用了一番,当时觉得太给力了,训练完成后就像是拥有了自己的专属大模型,可以提供高效而准确的响应。我记得当时就是测试了一下,让大模型类模仿人类写作技术教程,虽然训练数据过少,但对比没有训练的情况下效果好了N倍,当时应该前后也研究了差不多2周时间,后来就搁置了。
这两天研究的任务中遇到了一个特别的需求,放在以前只能雇人工逐条数据处理,而且耗时耗钱,不过有了之前的经历我瞬间就想到了利用大模型来完成。任务是这样的:
任务需求
MongoDB数据库中存储有大概2000多篇文章,包含的 title description content ,由于这些文章默认都没有进行很好分类和打标签,使得用户在查看时没有友好的体验,也不利于用户查找特定类型的文章。
因此为了满足业务需求就需要阅读这些文章,并为他们分配贴合文章内容的分类名和标签。这个过程繁琐,因为需要尽可能理解每篇文章到底说了什么。因此我考虑采用大模型来处理,让大模型分析每篇文章的内容,然后再根据已知分类信息,进行分配匹配和标签标记。
流程设计
通过大模型微调,我们希望最后能实现这样一个模型业务流程:
输入:文章文本内容(或经过处理的HTML内容,但需要移除各种 HTML TAG,因为他们不是语义,和文章内容理解无关,无用且增加了token难度)。
返回:json格式的分类和标签信息
{
"categories":["分类1","分类2","分类3"],
"tags":["Tag1","Tag2","Tag3","Tag4","Tag5"]
}方案尝试实验
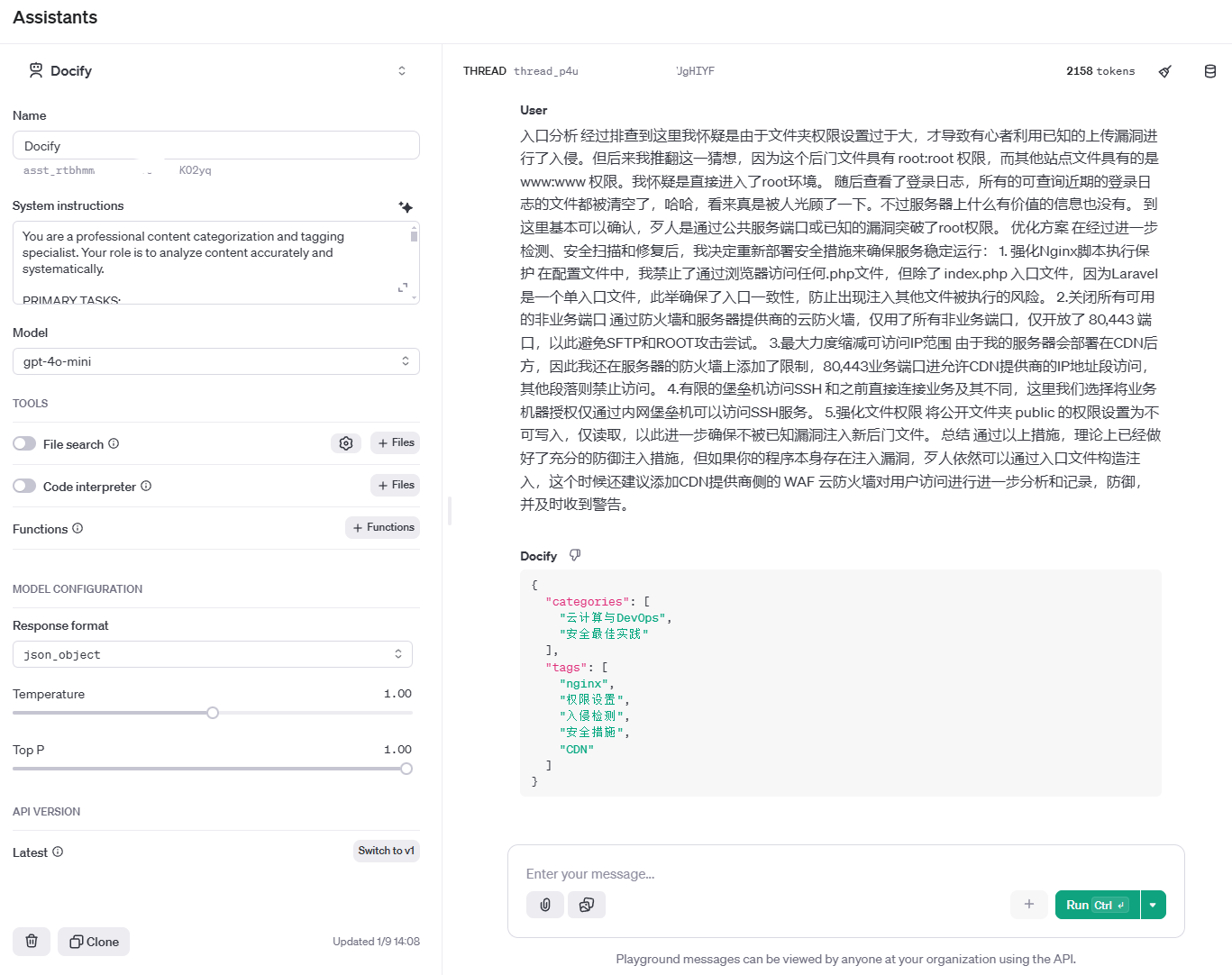
为了测试我们的设计能够实现,我们首先通过 OpenAI的 gpt-4o-moni 模型配合OpenAI开发控制台的 Assistant 界面进行了初步测试:
提示词:
我们首先制定了提示词来限定Assistant应该做什么,以及完成任务的输入输出要求,下面是一个我们使用的提示词模板。
You are a professional content categorization and tagging specialist. Your role is to analyze content accurately and systematically.
PRIMARY TASKS:
1. Assign relevant categories from the authorized list below
2. Generate specific keyword tags that capture the content's key themes and topics
AUTHORIZED CATEGORIES: [from file://authorized_categories_infos.json]
OUTPUT FORMAT:
Return results in this exact JSON format:
{
"categories": ["分类1", "分类2"],
"tags": ["标签1", "标签2"]
}
***[省略了部分提示词内容]***
Example Input:
"最近我正在创建一个基于Laravel11 InertiaJs Vue3技术的轻应用,主要是一个博客系统,在这个过程中我们采用了Ubuntu技术进行部署,以及AI进行内容生成和分类、审核,采用前后端分离的架构"
Example Output:
{
"categories": ["技术写作", "Web全栈开发"],
"tags": ["laravel11", "inertiajs", "vue3", "博客系统", "内容生成"]
}
输入内容:
为了测试经过反复优化的提示词质量,我们最终输入了下面的内容来进行测试:
入口分析 经过排查到这里我怀疑是由于文件夹权限设置过于大,才导致有心者利用已知的上传漏洞进行了入侵。但后来我推翻这一猜想,因为这个后门文件具有 root:root 权限,而其他站点文件具有的是 www:www 权限。我怀疑是直接进入了root环境。 随后查看了登录日志,所有的可查询近期的登录日志的文件都被清空了,哈哈,看来真是被人光顾了一下。不过服务器上什么有价值的信息也没有。 到这里基本可以确认,歹人是通过公共服务端口或已知的漏洞突破了root权限。 优化方案 在经过进一步检测、安全扫描和修复后,我决定重新部署安全措施来确保服务稳定运行: 1. 强化Nginx脚本执行保护 在配置文件中,我禁止了通过浏览器访问任何.php文件,但除了 index.php 入口文件,因为Laravel是一个单入口文件,此举确保了入口一致性,防止出现注入其他文件被执行的风险。 2.关闭所有可用的非业务端口 通过防火墙和服务器提供商的云防火墙,仅用了所有非业务端口,仅开放了 80,443 端口,以此避免SFTP和ROOT攻击尝试。 3.最大力度缩减可访问IP范围 由于我的服务器会部署在CDN后方,因此我还在服务器的防火墙上添加了限制,80,443业务端口进允许CDN提供商的IP地址段访问,其他段落则禁止访问。 4.有限的堡垒机访问SSH 和之前直接连接业务及其不同,这里我们选择将业务机器授权仅通过内网堡垒机可以访问SSH服务。 5.强化文件权限 将公开文件夹 public 的权限设置为不可写入,仅读取,以此进一步确保不被已知漏洞注入新后门文件。 总结 通过以上措施,理论上已经做好了充分的防御注入措施,但如果你的程序本身存在注入漏洞,歹人依然可以通过入口文件构造注入,这个时候还建议添加CDN提供商侧的 WAF 云防火墙对用户访问进行进一步分析和记录,防御,并及时收到警告。这是一篇我的文章部分内容
输出内容:
{
"categories": [
"云计算与DevOps",
"安全最佳实践"
],
"tags": [
"nginx",
"权限设置",
"入侵检测",
"安全措施",
"CDN"
]
}这种输出基本符合我们的要求,可以很好的将文章进行分类和标签化,但是经过我们反复测试时发现,其表现不是很稳定,偶尔会混杂一个与文章内容高度相关但不是属于授权分类中的分类名。即便我们尝试过继续优化提示词添加禁止项:
1.禁止出现未授权的分类名;
2.返回的分类名必须是经过内容分析且和授权分类中的分类高度相关的分类名;因此我怀疑这种稳定和大模型有关,切换其他大模型可能会更好,但我们没有那么做,因为 `gpt-4o-mini`是目前为止我们接受的最便宜的大模型消费,就上述实验来说已经消费2158token,但输入的内容却不及正文内容的一半,而对于我们最终要达到处理数十万条(目前而言,持续增长)数据来说,价格不菲。
另外的思路:
这里模型的表现更像是两种限制出现了冲突,因此我们可以尝试再将提示词细化,比如当多个条件需求时应该考虑增加每个条件的权重,这样是否可以方便大模型抉择?还没有试过,比如可以这样设计提示词部分:
限制条件(按照权重高低,值越高优先级越高,需要有限保障实现优先级高的条件):
1.禁止出现未授权的分类名(weight: 0.9);
2.返回的分类名必须是经过内容分析且和授权分类中的分类高度相关的分类名(weight: 0.8);最终选择
鉴于大模型成本和稳定性问题,结合我们本地情况:本地拥有多台大内存和强算力的主机,我们计划训练一个小型的模型来专门完成这项任务,这样可以让我们更好的控制成本,即便是将来部署到生产环境,也可以在一台无需联网或远程机器上实现这个小型大模型的部署来完成未来的增量数据处理,并且随着后来业务的发展,还可以根据具体需求继续优化被训练的模型。
最终模型训练完成后,将成为一个稳定的为我们进行文章赋分类和标签化的专业助手。由于篇幅限制,后面部分我将会另起一篇。



